The Time Series Refinery News.
Roadmap
User Interface
The current user interface has been seriously overhauled in version 0.9 and 0.10, and we will continue working on it to make it the best possible UI experience. And we have these two "big ticket" items.
- Provide a revamped Excel client. The current works as designed but has a number of limitations and shortcomings (some due to Excel itself). We at least want time zone support.
Data management
Data management is the core business of the tool; we will complete the existing tool set to achieve brilliance in this area, as time and budget permit.
- Extend the Python api to provide seemless tracking of model inputs and outputs. That will significantly augment the traceability of relationships between series and models. Model backtesting will be easier with this.
- Now that support for Pandas 2.x is there, there will be interesting performance possibilities in the future, specially with the PyArrow backend. PyArrow allows interoperability with other arrow-based data transformation tools such as Polars.
- Allow to perform history rewriting, as in: insert versions of a series older than the current.
- Allow to perform data supervision on formulas. Right now only stored series can receive supervised corrections.
- Associate series with classification schemes (or folder-like hierachies). Searching by name / metadata is powerful but people are used to browsing folders to find items. It can help discoverability of series.
- Data-mesh: move the sources definition to the database (currently in configuration files) and provide an API point and a Web UI to edit it.
- Data-mesh: provide an active mode, where events like series edition, renaming, deletion are propagated to its consumers for good effects (most notably the maintenance of the whole system's integrity, cross-instances).
- Have a notification hub for various events. People should be able to ask being notified on tasks failures, series (non-)updates, etc. and the hub use whatever preferred and available method (email, chat) to inform them.
- A better data model for Market Data. It is possible to represent them with naked time series, but with a number of downsides. A richer data model is being worked on to make it easy and reasonnable.
Storage
The current postgres-based storage system works very well and provides a fast transactional storage with good density. It will in remain the default for a long time. However we have a plan for something with better performance (less storage space, lower latency) and scalability (big-data scalability).
- High performance storage on the filesystem : have an alternative to postgres for the time series themselves. The catalog, metadata etc. will still reside within postgres. However with the time series on the filesystem we will get lower latencies (on read/writes), much faster dump/restore times (can get a bottleneck with big postgres databases) and potentially infinite scalabality if used in conjunction with a distributed filesystem such as CephFS.
- An alternative to postgres (with or without the high performance item above) could be to use sqlite, for a lightweight personal refinery-on-my-laptop deployment, without the hassle of deploying postgres there.
- Work on an alternative storage has started in late 2024 and we expect it to be tested around mid-2025. It may become ready by the end of 2025.
2025-08-04 Release 0.10.0
Developed between November 2024 and March 2025, this release brings significant enhancements to the editing experience and extends the powerful federation capabilities to groups. The time series editor has been redesigned as a 2D spreadsheet interface, while search functionality has been split to better serve both casual users and power users.
Federation, which previously allowed formulas to reference series from remote Refinery instances, now extends to groups. This enables true distributed scenario management across organizations.
Spreadsheet Editor
The time series values editor has been completely redesigned from a simple list to a full 2D spreadsheet interface. This represents months of work to bring Excel-like editing capabilities to the web interface:
- The new 2D table layout displays multiple series side-by-side with dates as rows and series as columns, making it easy to compare and edit related data.
- Cell editing works as expected - double-click to edit, type to replace, Enter to confirm. Values are automatically rounded for display while maintaining full precision internally.
- Rectangular selection with mouse dragging allows selecting blocks of data across dates and series. Hold Shift to extend selections, use Ctrl for multiple selections.
- Copy and paste operations work on rectangular selections - copy a block from one area and paste it elsewhere, with automatic date alignment.
- Keyboard navigation with arrow keys, Home/End, and Ctrl combinations provides efficient movement through large datasets.
- Fill operations help complete missing data - select cells with gaps and use the Fill NAs button to interpolate values.
- A toggle shows or hides pending changes, letting you review modifications before saving.
- Series creation mode allows initializing new time series directly from the interface with date ranges and values.
Search Evolution
The search interface has been redesigned with two distinct modes to serve different user needs:
- Basic mode provides a visual query builder where you construct filters by dragging and dropping conditions. No need to learn query syntax - just build what you need visually.
- Expert mode gives direct access to the powerful Lisp-based query language for complex searches involving multiple conditions and nested logic.
- Seamless mode switching - queries built visually in Basic mode can be viewed and refined in Expert mode, helping users learn the query language.
- Result limiting prevents browser overload when searching large catalogs - essential for instances with hundreds of thousands of series.
Federation for Groups
Groups (used e.g. for scenario management) now support full federation, matching the capabilities previously available only for series:
- Groups can reference series from multiple Refinery instances, enabling scenarios that span organizational boundaries.
- Bound groups work across instances - define a group structure centrally and have it populated from distributed sources.
- Group formulas can reference remote groups, enabling complex cross-instance scenario calculations.
- The group_find API works across federated instances with the same predicate system used for series.
- Remote group metadata is accessible, maintaining full traceability across the federation.
Groups Enhancement
Beyond federation, groups have received numerous improvements:
- Incremental updates - add or modify individual scenarios without replacing the entire group, dramatically improving performance for large groups.
- Metadata history tracking shows how group classifications and properties evolved over time.
- Horizon widgets provide consistent time range selection across all group interfaces.
- The group editor properly handles permissions, preventing unauthorized modifications.
- Group plotting respects horizon settings, updating charts dynamically as you adjust the time range.
Formula Capabilities
- The "date-filter" operator supports cron-like rules for sophisticated time-based filtering - keep only specific days of the week, hours, or complex patterns.
- New "group-from-series" operator dynamically creates groups from series matching criteria.
- "group-add-series" provides a dedicated way to add series to existing groups within formulas.
- The "cumprod" operator computes cumulative products, complementing the existing cumsum.
- Formula dependency tracking via the "depends" API helps understand which formulas use which series or other formulas.
- Access previous formula versions with "oldformulas" to see how calculations evolved.
- The series operator gains a "keepnans" parameter, preserving NaN values when they represent meaningful gaps rather than missing data.
Visualization Enhancements
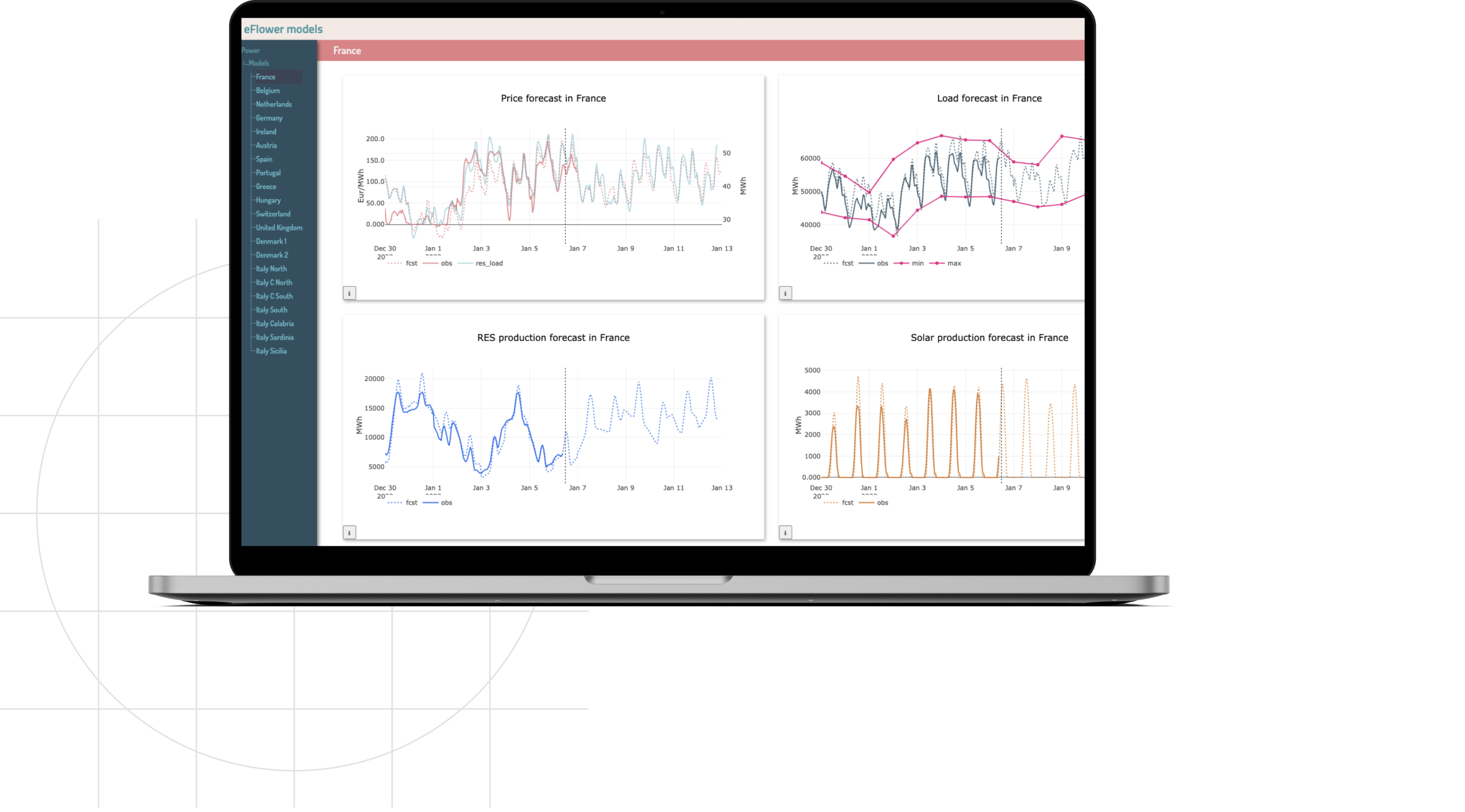
- Scatter plots now support 3 or more Y-axis series, up from the previous limit of 2, enabling richer correlation analysis.
- New candlestick charts provide proper OHLC (Open-High-Low-Close) visualization for financial data.
- Balance delta figures visualize differences between scenarios, making it easy to see impacts of changes.
- Group figures can display min/max ranges, showing the envelope of all scenarios in a group.
- Daily profile charts have improved hover text and properly labeled hourly x-axis.
- The dashboard system is now fully integrated into the main Refinery interface, eliminating the need for separate deployment.
Metadata & Auditing
- Complete metadata history tracking for both series and groups shows who changed what and when.
- API endpoints "old_metadata" and "group_old_metadata" retrieve any historical version of metadata.
- Case-insensitive name searches make finding series more forgiving.
- The "info" API provides high-level statistics about the Refinery instance.
Technical Improvements
- Fixed a long-standing issue where naive time series could incorrectly become timezone-aware during certain operations.
- Excel add-in now supports OpenID authentication for enterprise single sign-on.
- Advisory locks prevent conflicts when multiple users update the same series simultaneously.
- Permission checks throughout the monitoring interface prevent unauthorized modifications.
- Type annotations added across HTTP clients and core modules improve development experience.
- Various performance improvements from switching to more efficient libraries, though impact varies by workload.
2025-03-12 Release
Developed between July 2024 and March 2025, this release contains an important number of features and significant fixes.
We expanded the user interface, with notable enhancements to the edition aspects. The "groups" feature (scenarized time series) are being promoted to function at parity level with the timeseries. This work will also expand to the next release.
The dashboard system user interface has received a lot of attention, and work in this direction will continue in the next release.
Support for identification using OAuth2 + OpenIdConnect (part of the commercial offering) has been promoted to Beta status. We know have tested it with KeyCloak and AWS Cognito.
Work has started on a new experimental storage for the Time Series (and Groups).
Time Series
- The API get method has received a keepnans parameters to allow getting the erasures (Nans are used to indicate erased points).
- The formula cache manager has been made more robust against whole machine crashes or unattended restarts.
- In the formula system, we fixed an old issue with the resample operator, when doing upsampling - we were lacking contextual information to query enough data to have good values at the boundaries. This has been fixed using a) a new upsample operator (which makes it explicit) and b) an optional origin_freq parameter to the resample operator to make upsampling work well.
Groups
- Groups are an exciting new feature designed to enhance the use of time series with scenarios and facilitate the organization of series into cohesive "groups" that share the same time index. We're continuously improving this functionality and have now added federation support.
- We added a number of api points for groups: replace_metadata, group_type, group_insertion_dates and group_history. Full parity may be reached in the next release.
- The user interface is also being overhauled to match what we have for the time series.
User Interface changes
We continued on the path set in early 2024 - to establish a strong user interface for many interaction workflows. Most efforts in this release concern the time series views and edition capabilities.
- The formula editor has been enhanced with a helper widget to allow finding items by name, for instance series name, metadata name, etc. to make sure one builds robust queries from the get-go.
- A box filled with statistical information (time horizon, min, max, mean, percentiles), has been added to the editor view.
- The editor now allow copying time stamps and values in batch.
- For the edition of stored (primary) series, the editor now present the editable data as spreadsheat cells, with support for mouse and keyboard (arrows, shift and ctrl keys) events. It is possible to select a range of values. Selections can be copied, pasted and deleted. There are new buttons/actions to fill existing gaps within the existing values. The newly edited points are displayed on the graph while editing happens.
- In the formula decomposition view (showing its components), we have a widget to change the rounding, which helps presenting the data with a given format.
- There is a new creation mode, allowing to initialize a time series from the user interface with a range of dates and values.
Dashboarding system
A number of enhancements have landed there, mostly quality-of-life items.
- Dashboards are now completely integrated within the Refinery, under /dashboards. This alleviate the need to have another application deployment when it matters.
- A dedicated landing page allow to list and manage (create, delete) the dashboards and their associated plots.
- The group figure (a type of plot) has received new options and the possibility to add a range of scenarios.
- A new balance delta figure has been added.
- The nascent "balances" add-on to the dashboards is expanding. Quality-of-life enhancements have been added and will keep coming in the next releases.
2024-06-15 Release
Developed between September 2023 and June 2024, this release contains an important number of features and significant fixes.
Whole new packages will also be provided with the "Pro" (commercial customers only) version: a tool named "tswatch" to monitor the time series status (we often want to know if series are in a reasonable state of freshness) and a separate complete Dashboarding tool with a low-code/slick UI to create the graphs.
Experimental support for identification using OAuth2 + OpenIdConnect has been added and covers the API and UI. This is also part of the Commercial offering.
API points
- Added support for Pandas 2.2. The compatibility with the older Pandas (1.0.5 to 1.5.3) series is still guaranteed.
- A new inferred_freq api point has been added. It provides the median time delta between points and a quality indicator.
- The find search expressions now allow to filter on internal metadata.
- The Swagger UI has been completed with more information to help third party implementors for non-Python clients. Documentation, input types, etc. have been largely improved.
- The experimental authentication which has been added around the web UI and the API supports 3 flows: the application (normal, with a browser) flow, the machine-to-machine flow (for robots running server-side) and PKCE (for users using the refinery from a local Jupyter Notebook for instance). A preliminary simple security model based on readers and writers is provided. It may evolve into something more sophisticated, depending on feedback.
User Interface changes
This release is chock full of changes. First of all, the landing (home) page has been completely redesigned and now provides much more clarity and crisp information about where to go from there. We have added a general menu on the left, which eases navigation amongst views a lot. Lastly, a number of views have been enhanced, re-designed and sometimes completely rewritten, with drastic effects on performance and interaction quality.
- The formula editor has been rewritten from the ground up. The original version was a "successful POC" that was difficult to maintain. We did a complete re-design of the internals; this already shows up in a number of visual enhancements: the code editor shows errors/problems in a much clearer way, the tree editor is slicker and now allows to select series from the catalog for the "series" operator. More features will come in the next releases.
- The independent "tshistory" view (very powerful to look at the versions in a synthetic way, down to the versions of an individual point in time) has been rewritten and included as a mode of the "tsinfo" (time series info) view. It is now slicker and much more reactive than before.
- The independent "tseditor", allowing to edit primary series and also see the values of the underlying series of a formula, has been rewritten and is now slicker, much more reactive and agreeable to use. It is now possible to paste values from Excel and identify missing data with the "inferred frequency" option.
- The formula "batch upload" and "all formulas" views have been rewritten and now provides the same look and feel as the other views.
- A new "basket editor" has been fleshed out. It allows to list, create and edit baskets (pre-recorded filters to get series list from the catalog). Baskets can be used in the catalog searches as well as in formulas.
- In the task manager we now have a new "plan" tab that shows the tasks that will be scheduled in the next hours. In the tasks tab, the lazy scrolling view has been fixed, and an action to fetch everything at once has been added. This makes the filtering on column much more usable without hampering the UI responsiveness.
- In the catalog (search) view, we can now filter on the "tzawareness" of series. The metadata filter is more intuitive and reactive than before and should be much more convenient to use.
- In the "tsinfo" view, the formulas can now be unfolded step by step (using a slider), and also formulas containing the "findseries" operator can be unfolded (the found series then appear in place of the "findseries" expression).
New Tools
The commercial offering now comes with two new powerful packages: a time series "monitoring" tool and a full-fledged Dashboard system. While only distributed to commercial subscribers, these packages are Open Source.
- Time series monitoring has many angles, and one of them is the issue of freshness. The "tswatch" package provides a simple web UI to specify the series (primary or formula) you want to track. They will display in a prominent way those that are lagging behind (because a scrapper has been failing for some time or some other reason). In the case of formulas, we can see their decomposition in terms of primary series to diagnose which part of the formula is in a stale state.
- A time series management system eventually winds up collecting and producing to be shown to some people. At the end of the production pipeline, a dashboard is the most straightforward way to expose what's going on. Our graph library is linked to a web-UI that guides, restricts and documents the graph building process through a python-coded specification. This UI is open-ended: a developper can add any graph type to the current collection, with its own specification. Our graph collection includes the "table" format (timeseries joint on their indexes), a "scatter-plot" useful for statistical exploration and analysis, a "group" plot for weather (or otherwise) scenarios and a "balance" plot to follow any process with inflows vs outflows following. More graph types are on the way. The balances are fully instantiable through the web-ui. The dashboard layout is also built through a compact and easy to use UI to offer the best productivity to the users.
Technical Changes
- Through the REST API, the /series/state (get) route now accept a "timezone" parameter for the json path.
- The "refinery.cfg" configuration file is no longer used. Everything is set in the "tshistory.cfg" file.
- An annoying bug in the task scheduler (non-firing of some scheduled tasks) has been fixed. We don't use APScheduler any more.
2023-09-07 Release
Developed between January and August 2023, this release contains a number of new powerful features and also some internal changes. In this report we will separate these clearly.
API points
- A new very powerful search facility has been added, which is spelled .find. Find will take a lisp-expression string allowing to combine filters on the series name, metadata keys and values, and for the later permits to write inequalities. The query returns a list of "series descriptor": lightweight objects that provide the series name and source, and optionally their metadata. The documentation can be found there: API doc. This will probably replace the older .catalog API point, which is in comparison to .find less convenient to use.
- To complement the find api point, we added a number of end points to facilitate the management (creation, listing, deletion) of persistent named search queries under the name of baskets.
- The filtering feature is also made available to the formula system. It is possible to e.g. add series over a findseries dynamic query.
- The .update_metadata method now actually only updates the metadata rather than replace it. For this behaviour, we introduced .replace_metadata.
- Formulas got a number of new operators: trigonometric operators, ** (exponentiation), sub (series subtraction), abs, round (rounding).
User Interface changes
- In the tasks manager list, it is possible to filter the service, input and status columns. This is very convenient to find failed tasks or tasks that are concerned by a given input, etc.
- The task manager list now uses lazy loading for its initial display. This helps a lot when a very long tasks tail is kept there.
- In the tsinfo view, we show the series source - it will be marked "local" if it comes from the main source.
Technical changes
- The minimal Python version is now set to 3.9, and pandas 1.5 support has been added.
- The data model has been simplified for series and groups to enable the filtering features.
- The tshistory.cfg configuration file now contains everything needed. The refinery.cfg file is deprecated.
- Data-mesh: the handling of an unavailable (for whatever reason) secondary source instance is now smoother. We get the local series and those of the currently available secondary sources.
- Storage: the max-bucket-size value has been set from 250 to 150. This will provide a more optimal (on average more compact) chunking strategy.
- Core packages now have a __version__ attribute. The deployed version is also stored into the database and is checked at startup time against the packages version.
- Migrations: a generic tsh migrate command has been added. It will use information in the deployed package versions and what is stored in the database to determine the exact migrations steps to run and actually run them.
The prehistory
Genesis of a time series cache
The TimeSeries Refinery started in 2017 as an experiment to plug a logistical hole between on one hand, a "big data" enterprise time series silo, and on the other hand people doing analysis using Excel (and sometimes Python).
The Excel sheet could receive data from the big data silo but there were a number of downsides working like this:
- manually overridden values in Excel were overwritten at pull-from-the-silo time
- the Excel sheets tended to grow too big: they performed poorly and tended to become intractable
- the Excel sheet calculations and expert overrides were not easily shareable
- the Excel client would regularly blow up and lose its settings
- at peak hours (in the morning) the big data system tended to answer slowly and randomly crashed
So we designed a "simple cache" for the silo's versioned time series and another Excel client to talk to our cache. The benefits became quickly clear:
- the "cache" would regularly update itself from the silo, hence the morning latencies went down drastically
- it also provided the ability to effectively save the analyst's data overrides as a new version that was kept from one refresh to the next (unless upstream values had been changed)
- it suddenly allowed the analysts to save their own hand-made series (either "expert values" or outputs of computations or models) directly from Excel, and of course from Python too
- everything in the "cache" was easily shareable, including from Python since we devised a simple but effective Python API to use it
- it was soon possible to quickly build reports and dashboards from what was in the "cache"
- we provided simple but effective ways to browse and display the series catalog and show the curves - which was either clumsy or impossible with the central IT managed time series silos
Adding computations
That successful initial success opened the road to the next step: moving computations out of Excel. After months of observing analysts' workflows with Excel it became clear a notion of computed series had to be added to the "cache". When that was done, around 2019, using an elegant domain specific language for time series under a clean and simple API, the Time Series Refinery was truly born.
We chose the simplest syntax available for the formula language: Lisp. This was immediately picked up by analysts (it is after all simpler than the Excel formula language or the ubiquitous VBA) and they started to build very sophisticated formulas made of formulas ... down to stored series of course. We added features to track formula dependencies and show and edit formulas from within the browser. A low-code platform was born.
Lastly, we also coupled to the timeseries (stored and computed) system with a task manager fit for the purpose of managing scraping and models tasks. Simple and lightweight, it provides the maintainers of the Information System a great deal of overview of the health of the system and again, a lot of autonomy.
Towards a Universal Time Series Information System
At that point in time though, people from other commodities or topical activities (e.g. hydrology, meteorology) had started to use it by setting up their own "cache". Quickly enough, it was understood that some "caches" would be interested in the data of another (the meteo time series are typically a cross-interest item as they are used as inputs in a variety of forecast models), and that duplicating data would be a bad idea. We came up with a straightforward implementation of the "data mesh" concept and soon we had a web of connected refineries instances. It turned out it would then be possible to aggregate many of them into some kind of "data hub" for further downstream usage. This is the basis of the current EnergyScan commercial offering. While doing so we also made a number of things better:
- the catalog browsing provided nifty ways to filter series on name and metadata
- it was possible to have a detailed view of each series (either stored or computed)
- the API had grown two operating modes: direct mode with a postgres connection string, and http mode using an http uri; both behaved exactly the same way
- a number of subtle and generally difficult issues pertaining to naive vs timezone aware time series, correctness and performance issues in the formula interpreter, had been ironed out
- a promising (albeit still experimental) time series groups features was brewing, serving the needs of non-deterministic meteo forecasts
- a powerful online auto-documented formula editor to boost analyst's productivity
- a (very important) protocol to use the formula system as a proxy for tier time series silos was devised and put in production (what we call the "autotrophic operators")
- a cache system on top of the formula system was devised to help with compute-heavy formulas
It is on top of these robust foundations and years of hard work on the ground that we are confidently bringing the TimeSeries Refinery to the commercial open source sector. Its pupose is to reduce the often tiresome Analysts / IT back and forth communications by giving the maximum amount possible of autonomy to the former, while discharging the later from many chores. We hope it will be a resounding success !